Cheney-Lippold, J. 2017. Introduction. In: We Are Data : Algorithms and The Making of Our Digital Selves. New York: NYU Press, pp. 1-32
The literature emphasizes that in today's data-driven environment, we are increasingly defined by algorithms as "measurable types." In other words, the identity we present in various systems is no longer the "I" we describe ourselves, but a classification template composed of fragmented data, such as browsing history, location, consumption habits, and biometrics, used in scenarios such as advertising, platform governance, and risk assessment. These classifications often have nothing to do with personal subjective identity.
The article uses several examples to illustrate the drawbacks of algorithms: for instance, Google's age or gender labels inferred from behavior are merely operational results under advertising logic; facial recognition systems, due to uneven training data, are more likely to identify white people and less likely to identify people with dark skin, exposing how algorithms can replicate existing social inequalities; the Chicago Police Department uses data to generate "heat lists," directly transforming statistical model outputs into real-world law enforcement tools, allowing people to be managed based on their data-driven "risk" status. The author points out that in data-driven governance, people are gradually losing their voice.
Algorithms, operating in an opaque "black box," determine who is considered "high-cost," "unreliable," or "at risk," with users often unaware of how these judgments are formed and finding it difficult to refute them. Simultaneously, algorithms make judgments based on biased existing data, leading to the replication and reinforcement of historically established social inequalities, such as racial or class biases, which are often presented as purely statistical or technical issues rather than political ones. As this operating method permeates our digital lives, subjectivity also shifts. Users in the online world are no longer treated as complete individuals but are dissected into analyzable and tradable "dividuals," creating a disconnect between personal subjective experience and the identities constructed for us by algorithms.
Black Box:
A black box refers to a system whose internal operations are opaque, where the outside world can only see the inputs and outputs but not the internal rules or processes. In the context of data and algorithms, this typically manifests as recommendation, rating, and prediction systems or business decision engines. Users can see what data they are given, as well as the decisions and results given by the system/platform, but they cannot see how the algorithm transforms the inputs into the output step by step.
The author further pointed out that this transformation embodies a new form of power, namely soft biopolitics or “modulation,” and uses Deleuze’s theory of “societies of control” to show that modern algorithmic control is different from traditional direct oppression, but is a kind of “continuously modulated” control. This constraint is constantly self-shaping and reshaping, and our identity as the subject of algorithmic interpretation will also change over time.
Reflection of Workshop
First, I checked the information collected from me in Xiaohongshu's settings. I discovered that not only my usage behavior on the platform was being collected, but also my phone information, such as location, contacts, and even my face, were being collected as data. I was actually quite shocked. Although I knew my data would be collected, I didn't expect so much! And I have no idea how the platform processes my data!
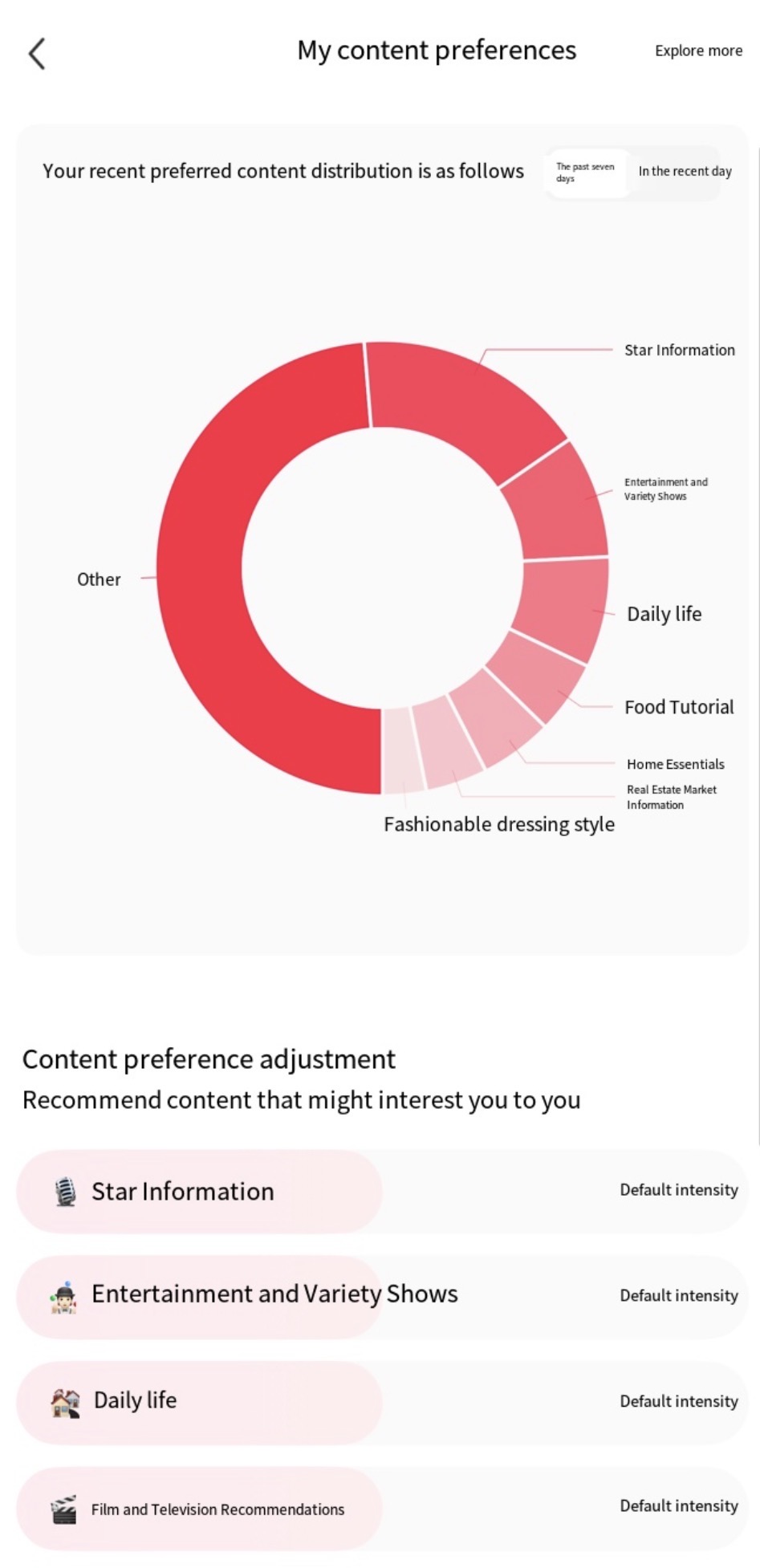
Next, I checked the interest tags and content preferences generated for me by the algorithm on the same social media platform. I found that most of these categories were inferred from my usual browsing, liking, saving, and dwell time. However, there were also some categories that I wasn't interested in and even found somewhat inexplicable, such as 'Real Estate News' and 'Celebrity Entertainment'. I was very curious about how the platform calculated my data to assign me these tags. Therefore, in the workshop, I used Sumpter's Method to simulate the algorithm's classification process.
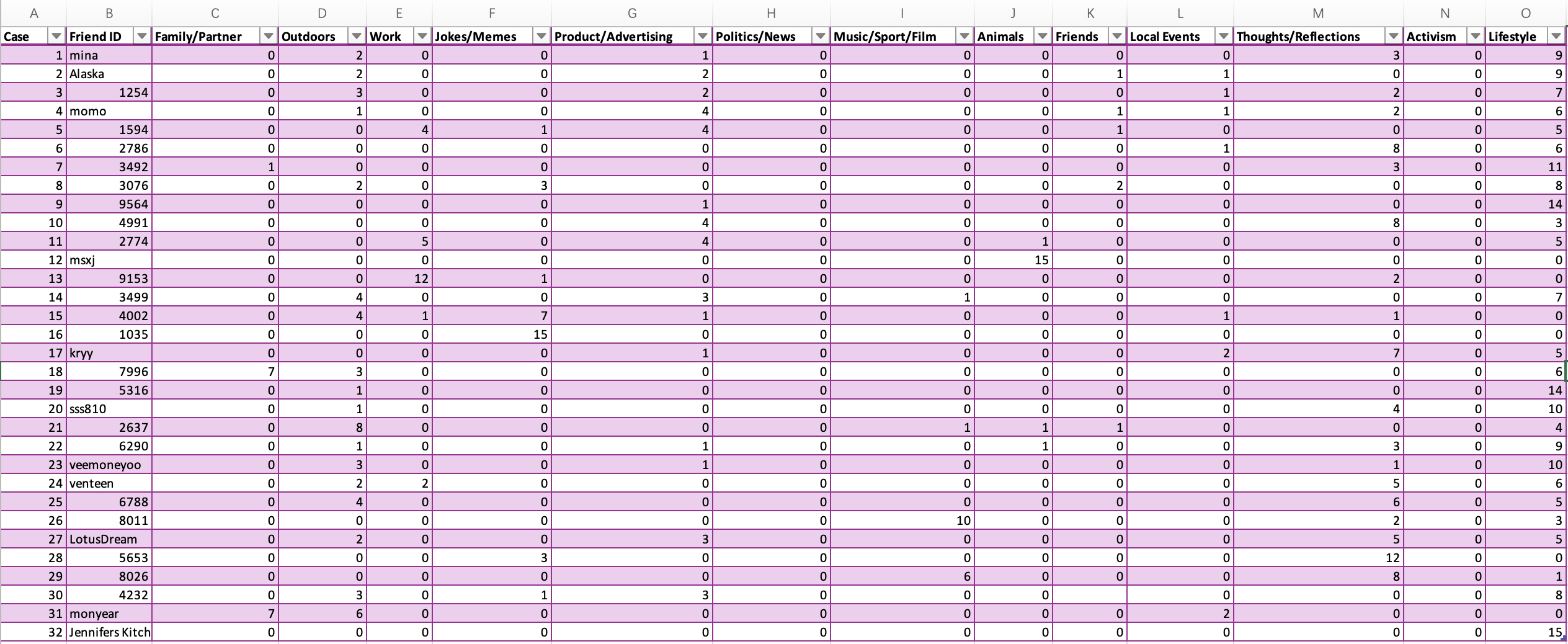
Sumpter initially analyzed his data by manually scraping his own Facebook data: he selected 32 friends and coded each person's 15 most recent posts into 13 categories based on topics, such as: family/partner, outdoors, work, jokes/memes, products/ads, politics/news, music/sports/movies, animals, friends, local events, thoughts/reflections, activism, and lifestyle. This resulted in a 32x13 table showing how many posts each friend made under each topic category.
He then used principal component analysis (PCA) to simplify these 13 dimensions into two main dimensions: one is "public vs. personal" (whether a person posts more about their private life or news and events in the public sphere), and the other is "culture vs. workplace" (whether they are more focused on cultural topics or work-related lifestyles). Finally, he performed k-means clustering on these two dimensions, roughly dividing his friends into three categories: those who mainly share private or family content, those who mainly post work-related content, and those who mainly comment on news and culture.
PS:I will present the specific process of my Sumpter Matrix simulation algorithm, as well as the subsequent analysis using PCA and k-means, in Assessment 1—critical reflection essay 🥸.
However, I found that Sumpter's Method still cannot truly simulate the classification process of an algorithm. First, this method relies on my subjective understanding of 32 friends and 13 topic categories to manually label and select variables, while real platform algorithms often incorporate hundreds or even thousands of features, including clicks, dwell time, sharing relationships, browsing history, and location data—all of which are ignored in the simulation. Second, the simulated classification is only an analysis at a specific point in time, while actual recommendation algorithms continuously update and adjust user profiles in real time which is a continuous process. Therefore, Sumpter's Method cannot be considered a complete "simulation" of an algorithm; rather, it uses a simplified and artificially designed model to help understand the logic of "classifying people with data", rather than precisely replicating a real-world algorithm system.